Abstract
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. We propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations.
Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals.
T3VIP is the first generative model that provides an RGB-D video prediction of the future for a static camera.
Motivation
From an early age, humans develop an intuitive understanding of physics, capable of predicting the dynamics of the 3D world. This cognitive model, which is learned via our interactions in the real world, enables us to generalize from past experience and predict the future observations of a novel scene through reasoning about the motion in 3D space. Furthermore, by equipping us to foresee the consequences of our actions, this mental model allows us to decide how to interact with the world and manipulate unseen objects towards our desired goals. Similarly, for a robot collecting unlabeled RGB-D video sequences autonomously, the ability to comprehend the dynamics of the surrounding 3D world and predict its likely future developments is of high value for acquiring real-world manipulation skills.
Our goal is to develop a 3D world model for autonomous agents based on their past unlabeled experience. We consider the problem of 3D video prediction, where, given a sequence of previous RGB-D frames, a generative model aims to capture spatial and temporal representations of the world and predict the RGB-D frames of the future.
The main contributions of this work are:
- A stochastic 3D video prediction model making long-range predictions via reasoning about rigid transformations in the scene for both action-conditioned and action-free settings
- An unsupervised learning framework for predicting the 3D dynamics of a scene solely based on unlabeled 3D point clouds and 2D images
- The utilization of automatic hyperparameter optimization to fully leverage all available observational cues and reduce the need for human expertise, and
- An interpretable 3D world model outperforming 2D models on model-predictive control
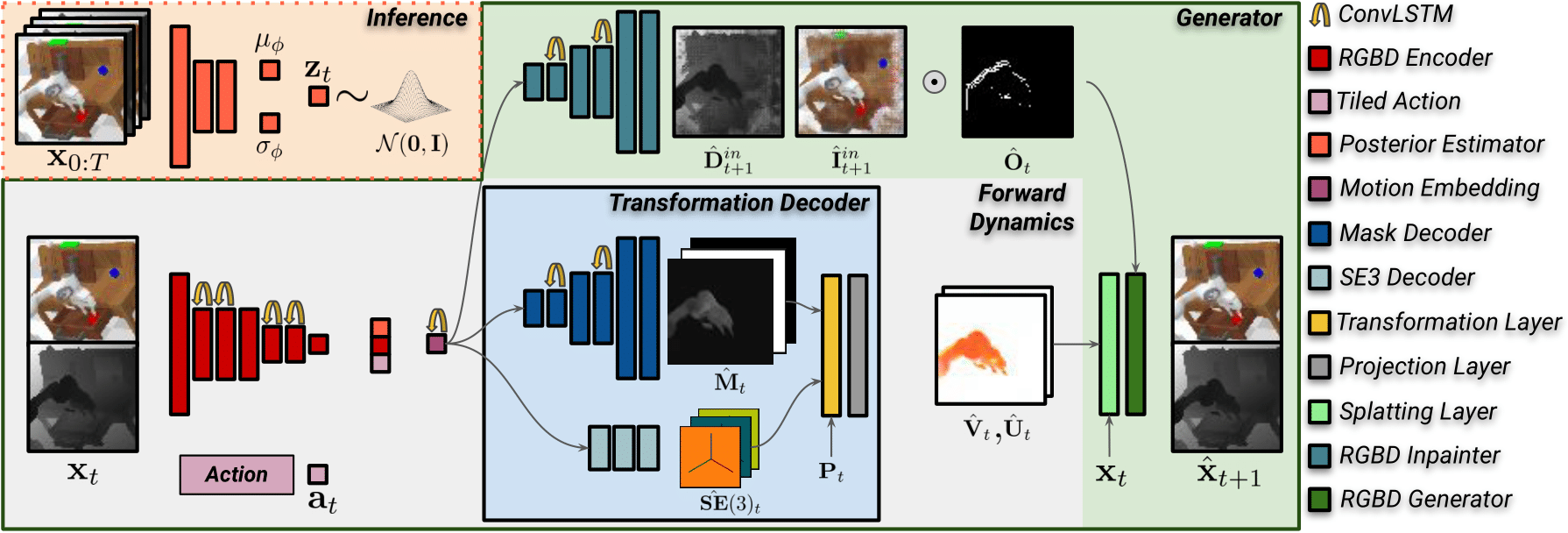
Method
Our model consists of two components: a recurrent generator network and a unit Gaussian prior distribution.
Recurrent generator network: T3VIP explicitly models the 3D scene dynamics to generate the next RGB-D frame.
Unit Gaussian prior distribution: accounts for the stochasticity at test time by employing a separate inference network used only during training.
Furthermore, we utilize observational cues to learn from unlabeled data and we automate the determination of the optimal hyperparameter configurations of our model.
Experiments
We evaluate T3VIP for RGB-D video prediction on both simulated and real-world datasets.
RGB-D PredictionsIn our experiments, we compare our stochastic RGB-D video prediction model to the following well-established RGB video prediction baselines CDNA, SNA, SV2P. We train all models for 200K steps. We condition all the models on the first two frames and train them to predict the next ten frames.
Our T3VIP model successfully makes long-range RGB-D predictions across three datasets via reasoning about the 3D motion, while the baselines cannot reason about the scene's geometry. Furthermore, our model significantly outperforms baselines on the DexHand dataset (where much self-occlusion is present) in the RGB metrics while achieving on-par performance on CALVIN and Omnipush datasets.
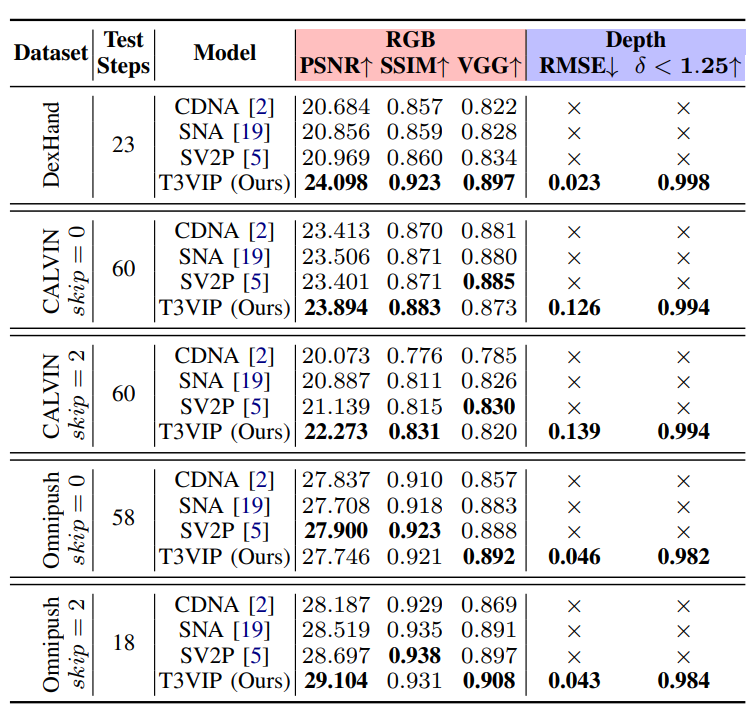
T3VIP produces sharp flow fields and sparse occlusion masks. This indicates that our model learns to reason about the 3D dynamics of objects in the scene and generates the next frame primarily using the predicted 3D motion and only inpainting those sparse occluded regions. Besides predicting long-range future depth maps, our model also produces sharper RGB images than baselines. The main reason for this is that beyond the reconstruction loss, our model also encourages sharp scene flow and optical flow fields.
 CALVIN
CALVIN
 Omnipush
Omnipush

To evaluate the effectiveness of our 3D-aware world model and compare it with a 2D world model (SV2P), we conduct a 3D servoing experiment in the CALVIN environment. The goal of this experiment is for the robot arm to reach the user-defined goal point as closely as possible. To this end, we employ iCEM, an enhanced version of the cross entropy method, which utilizes the learned world model to search for the best action trajectory that leads to the desired goal point. Please note that although the goal point is in 3D, a 2D world model is unaware of the target's depth measurement and can only comprehend the corresponding target pixel.
We observe that although SV2P can successfully reach the pixel coordinates of the goal point, it often misses reaching the user-defined 3D target, as it suffers from the inherent ambiguity of 2D vision in capturing depth. In contrast, our model comprehends the goal in 3D, effectively predicts the 3D dynamics of the robot's end-effector, and successfully reaches the target point.
Conclusions
In this paper, we proposed transformation-based 3D video prediction (T3VIP) as a multi-step RGB-D video prediction approach that explicitly models the 3D dynamics and the rigid transformations of a scene. The unsupervised formulation of our approach leverages visual and geometric cues in the environment to learn real-world stochastic dynamics without human supervision. We also employ automated machine learning techniques to aid our model in finding hyperparameter configurations that exploit observational signals and achieve high accuracy. In extensive experiments we demonstrate that T3VIP learns an intuitive 3D world model, which outputs interpretable scene and optical flow fields and effectively enables an agent to reach 3D targets.
Regarding future research, we believe that, given the ability to learn long-range RGB-D predictions of the future from unlabeled experience and the advanced capabilities of a 3D model in contrast to a 2D model, employing 3D models is a promising direction to autonomously learn real-world robot skills.
Publications
T3VIP: Transformation-based 3D Video Prediction Iman Nematollahi, Erick Rosete-Beas, Seyed Mahdi B. Azad, Raghu Rajan, Frank Hutter, Wolfram Burgard Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022 PDF
BibTeX citation
@inproceedings{nematollahi22iros,
author = {Iman Nematollahi and Erick Rosete-Beas and Seyed Mahdi B. Azad and Raghu Rajan and Frank Hutter and Wolfram Burgard}
title = {T3VIP: Transformation-based 3D Video Prediction},
booktitle = {Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = 2022,
url={http://ais.informatik.uni-freiburg.de/publications/papers/nematollahi22iros.pdf},
address = {Kyoto, Japan}
}





